In this post I will look at the high-performance JavaScript library that I built that sits atop the Huninn Mesh RESTful API for sensor data. It was explicitly designed for us in JavaScript applications (AKA single page apps).
The Need for a Client Side API
Our RESTful API, quite deliberately, limits the form of data that it serves: a user can request a an hour's data, a day's data, a month's data or a year's data for a given sensor. The reasons for this are set out elsewhere in detail (but the answer is performance). Where a user wants to view data that falls outside of one of these intervals, then client side manipulation is usually required. Specifically, the cutting and splicing together of responses from one or more web requests in order to assemble the time-series data set the user does need.To illustrate, the API does not support the following 'traditional' parameter driven query:
/getSensorData?from=1451649600&to=1451736000&samples=20
This query represents a request for 20 samples spanning the period noon on January 1, 2016 through noon January 2, 2016 (UTC). Visually:
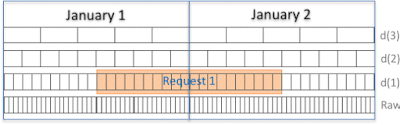 |
| Huninn Mesh does not support a traditional from-to style API. Note that Raw, d(1), d(2) and d(3) represent the raw sample data and its decimations, as discussed in another post. |
 |
| There are multiple combinations of API requests that can be made to fulfil a request that spans a day, in this case, two requests are made. |
In its simplest form, our API moves the query parameters into a JavaScript object that's passed to an API with an appropriate callback.
hmapi.requestTimeSeries(
{ sensor: ae43dfc8, from: 1451649600, to: 1451736000, samples: 20 },
myCallback
);
Library Implementation: Our First Attempt
Our first attempt to implement this API took a simple and straightforward approach to the problem. The library:
- always chose intervals of days when downloading sensor data, regardless of the actual period of interest to the user;
- ran on the main browser thread;
- made XHR requests to the server;
- rebuilt time series objects whenever an XHR response was received; and,
- made callbacks whenever data in a time series was updated.
It worked well - page load times were reduced from the order of six seconds to two seconds with a clear browser cache and much less with a primed cache. We were able to ingest HTTP responses at the rate of approximately 60 per second.
More importantly, the library exposed a range of issues on the browser-side.
Weakness Exposed
From the outset, our RESTful API was designed to be deployed on a SPDY capable web server. We chose Jetty 8.x as our servlet container with this in mind. However, at the time we wrote the system, neither Internet Explorer nor Safari supported SPDY. Not surprisingly, we saw worse performance on these browsers than on Chrome or Firefox which had SPDY support.Regardless of whether SPDY was used or not, with an empty browser cache, we found that performance (the elapsed time to load a complete time series) rapidly degraded as the length of the time series was increased. This was due to the decision to choose intervals of a day for all server requests. Not surprisingly, when the time range was extended to a year for graphs of temperature, pressure and humidity, performance degraded because the library increased the number of HTTP requests to 1,095 HTTP or so.
Furthermore, as I noted earlier, we limit graphs to 200 data points (that is, 200 data points were graphed irrespective of whether the time range was a year or a day). The library varied the number of samples requested according to the time range and, as a consequence the browser cache hit rate declined.
 |
| At a small time range, for example an hour, the API might choose the raw time series whereas for a long range of, for example a year, the d(4) decimation might be chosen. |
Additional (substantial) issues were identified including the following, non-exhaustive, list:
- for each completed XHR request, a graph was redrawn - with a large number of requests, this led to a 'spinning beachball' as the browser's main thread was fully occupied drawing graphs (this was particularly bad on Firefox and Chrome which used SPDY and, therefore, received responses more quickly);
- the six connections per host limit for the HTTP 1.1 based Safari and IE imposed a significant throttle on throughput leading to longer load times before a graph was fully drawn (but mitigating the spinning beachball problem mentioned earlier);
- users tended to rapidly navigate back-and-forward between views over different datasets often before graphs were fully drawn leading to very large backlogs of XHR requests building up;
- probably as a result of the prior point, we managed to crash various browsers (particularly mobile) during testing due to memory issues that, we thing, were related to very large XHR backlogs which were exacerbated by a server bug (aw snap).
Requirements Real JavaScript Library & API
Learning from our prototype, we arrived at the following requirements for the version 1 library:- Off main thread dispatch and processing of time series requests.
- In-memory cache to enable substitution of time-series as well as serving of stale time-series.
- Prioritised download of time series absent from the cache.
- Active cache management for memory.
- Smart(ish) API usage.
- Rate limiting of XHR requests (stop SPDY floods).
- Debounced callbacks.
- Detection of missing data.
The following sections provide more information on how these requirements were implemented in software.
The implementation was driven by one additional overriding requirement: that of cross browser compatibility including on Mobile where iOS 8 and Android 4.x were our baseline.
The implementation was driven by one additional overriding requirement: that of cross browser compatibility including on Mobile where iOS 8 and Android 4.x were our baseline.
One final note, I also opted to go vanilla JavaScript with zero external library dependencies. Thus, I was limited to APIs supported across the latest versions of IE, Chrome, Firefox and Safari - desktop and mobile - circa March 2014. That is, no Promises, no Fetch, no ServiceWorkers and no third party shims or polyfills...
How it Works
The final implementation is best explained via an interaction diagram:
 |
| An interaction diagram illustrating the major components of the library. Asynchronous events are shown being initiated by a blue event loop. Areas shaded orange represent the Huninn Mesh library and those in blue represent core browser features. |
This diagram, though simplified, gives a good sense of how data moves through the system. The blue loops indicate entry points for asynchronous events. The system flow, in the case of data that needs to be downloaded, is roughly as follows:
- The user requests data for a sensor over a time range.
- The Time Series object checks with a cache object which has no data for the given range.
- The Time Series object delegates download, making a request via a Dispatcher object.
- The Dispatcher object, having made sure that there is no outstanding request for the same data, posts a message to a Web Worker with details of the resource requested.
- The system invokes a callback in Handler object in a worker thread.
- The Handler creates an asynchronous XmlHttpRequest and sends it.
- When the XmlHttpRequest completes, a callback in the Handler object is invoked.
- The Handler then performs various functions including JSON decoding, error checking, parsing of HTTP headers to determine expiry, gap detection in the time series data and finally, generation of statistics about the time series.
- Having done this, the Handler posts a message back to the main thread, containing the resulting data.
- The Dispatcher receives a callback containing the result from the Handler and invokes a callback on the Time Series object.
- The Time Series objects passes the result to the local cache.
- The Time Series then checks to see whether it has all of the data chunks required and splices them together.
- The Time Series sets a timer.
- When the timer fires, the Time Series checks the its freshness and passes the result to the user function that graphs the result.
Off Main Thread Processing
All XmlHttpRequest processing was moved to Web Workers.From the outset, I was concerned that this might be overkill: I reasoned that the XmlHttpRequest is limited by IO and a worker would add enough overhead to cancel out any benefit. In particular, the JSON response from the server has to be parsed in the Web Worker, manipulated, then cloned as it is passed back to the main thread.
In practice, we found that we got a significant, but inconsistent, performance improvement by moving to workers.
In particular, Chrome (Mac OSX) was idiosyncratic to say the least: timing was highly variable and, indeed, browser tabs sometimes fail under load "aw snap". I tracked this down to postMessage from the worker to the main thread: sometimes, successive calls to this API would take exponentially longer than the prior call, ultimately, crashing the browser tab after the last successful call took about eight seconds. (This problem got fixed somewhere around Chrome 41.)
Putting this issue with Chrome aside as a temporary aberration, the addition of a single Web Worker doubled XmlHttpResponse ingestion rate to about 120 responses / second with a clean cache.
As noted above, we perform additional tasks in the worker on the time series beyond parsing the JSON response: we also parse date/time headers, identify and fill gaps in the time series (missing measurements) and also generate statistics about the series (frequency distributions of values, etc). None of this work was done in the prototype library and so I can't comment on how slow it would have been if this were handled on the main thread...
Prioritised XHR Dispatch & Rate Limiting over SPDY / HTTP 2
Switching on SPDY on Jetty 8 led to immediate problems at the server: Jetty (version 8) would stop responding with all of its threads waiting on a lock - we spent a long time trying to work out why and we never got to the bottom of the problem. The clever Jetty folks seem to have fixed this in version 9, however.We hit the server with an very large number of requests in a very short time from a single browser session. It was not unusual for us to dispatch 1,800 XmlHttpRequests in half a second (to retrieve temperature, pressure and humidity time series for a year for each of 50 floors in a building).
As noted earlier, in testing, we encountered browser instability when we created a large number of XmlHttpRequest objects. Therefore, we had to reduce the number of outstanding requests and manage dispatch ourselves.
The Dispatch object manages tasks performed on one or more web worker threads. Running on the main thread, it maintains two queues: high and, low priority requests, and also the number of tasks dispatched to each of the worker threads it manages. Tasks are posted, round-robin, to each thread in the worker pool in an attempt to balance load. The Dispatcher also tracks the number of messages (tasks) posted to each web worker. This measure acts as a proxy for the maximum number of outstanding XmlHttpRequests and thus is the basis of rate limiting. Only when there are no high-priority tasks pending do low-priority tasks get posted.
Thus, the Dispatcher performs rate-limiting, attempts to keep each worker equally busy and manages download priorities. Profiling showed that the overhead of the Dispatcher was tiny.
For the record, after some experimentation, I found that four worker threads each handling a maximum of 25 tasks gave the best performance and worked reliably across iOS mobile Safari, through Chrome, Firefox, IE and even Mobile IE. Using these settings, a maximum of 100 XmlHttpRequests can be active at any moment.
In-Memory Cache
The value of download prioritisation becomes apparent when discussing the in-memory cache. The cache contains API responses returned from the worker. That is, these are not the compete Time Series objects but the objects that are spliced together to create the Time Series requested by the use.The biggest 'win' from the cache was that it allowed response substitution and this, in turn, allowed download prioritisation.
Response substitution is simple:
- if the cache has a response with the wrong number of samples, then this response can be substituted;
- if the cache has a response that has expired, then this response can be substituted.
Substitution, means spliced into the Time Series response and pushed to the user. This implies that some time series objects have varying sample rates and/or missing data. Users can, of course, opt-out and disallow substitution but, in our own apps, nobody ever did - graphs with the wrong number of samples are better than no graphs at all.
From the end-user's perspective, the effects of the in-memory cache were dramatic to say the least with the entire app appearing to become far faster.
Requests for which there is no substitutable item in the cache are immediately requested from the Dispatcher at a high-priority. Requests that have a substitute item are requested at a low-priority. I should note that the cache was managed so that, data for individual sensors was dumped from memory ninety seconds after the last watcher of that sensor un-registered themselves.
Caching and download prioritisation and proved so effective that we experimented with cache pre-population (at a small sample size) - ultimately, the system was so fast that this did not prove to add much to an already fast user experience.
Debounced Callbacks
Time Series objects were assembled progressively from multiple chunks of data. On availability of a new data 'chunk', this data was spliced into the Time Series and a callback triggered. Callbacks in user-land typically used a requestAnimationFrame and performed DOM manipulations (graph redraws, etc).The sheer number of Time Series objects in use meant that we ran into an issue where we flooded the UI thread with work - we measured 1,400 callbacks/second at times. For this reason, we debounced callbacks, to 500ms per Time Series object. Again, although somewhat counter intuitive, this proved highly effective at keeping the UI responsive.
Retrospective
The Huninn Mesh JavaScript library weighted in at ~9,000 LOC (commented). It is the by far the largest chunk of JavaScript I have ever written. If I had my time again, I would:
- choose TypeScript rather than vanilla JavaScript classes;
- do a better job of unit-testing;
- do a better job of estimating the project.
I found JavaScript really very nice as a language, I found that Web Worker support in particular was very good and that I could deliver what was IMHO an incredibly fast app into the browser. However, coming from a Java background, I really missed static typing and, in the larger sense, the convenience offered by TypeScript.
I did a poor job of Unit Testing. My day job is as a manager, and I found myself omitting tests due to deadlines. I'm not proud of myself - this is a pitfall I encourage others to avoid. I also under-estimated the effort required to author the library. It took me four months in total - about twice what I expected (although I had something working from about the six-week mark - all else was new features, optimisation and re-factoring as I learned the ropes).
The Results
The results quoted here are for four Web Workers and a throttle of 100 outstanding XMLHttpRequests.- My JavaScript library clocked a sustained data ingestion rate of 220 time series chunks/second from a clean browser cache (amazingly, I reached 100/second on an iPhone 4s).
- Results for a warm browser cache were surprisingly variable. In some cases, I saw well over 400 tx/sec and in others, no better than an empty cache.
- Each additional Web Workers delivered incremental performance improvements but these were small after the second worker thread (Amdahl's law at work?)
- HTTP/2 did exactly what it claimed: running tests on the server with a warm server cache and then switching HTTP/2 on/off led to a sustained improvement in ingestion rates of over 40%. I should note that I expected better! (Of which, more in a moment.)
- It worked on all modern browsers (which, if my memory serves me well were IE 11, Chrome 39, Firefox 36 and Safari 7). Surprisingly, Chrome proved the least stable - particularly with developer tools open, I saw a lot of crashes. In fairness, I did most of my debugging in Chrome and so there's some serious bias in this observation.
- Safari held the speed crown - from a clean start of the Safari process and hitting the browser cache, I saw 800/tx sec in one test. More generally, however, Chrome beat all contenders beating Firefox by about 10% and IE by about 40%.
By way of a wrap up, the RESTful API design, client and server caching of HTTP results coupled with a multi-threaded client side library written in JavaScript delivered massive performance improvements to our app taking us from a so-so multi-second refresh to a sub-second blink and you'll miss it.
This done, the JavaScript API allowed us to think more broadly about visualisation. Building managers are not interested in the average temperature for a building: they want to see every aspect of its performance over time scales varying from hours to years over hundreds of sensors. With our new API, it became easy to answer yes to challenges like this.
No comments:
Post a Comment