In my previous two posts about Hunnin Mesh, I discussed the nature of the
Huninn Mesh network and the
architecture, abstractions and constraints of the Huninn Mesh server.
In this post, I will go into more detail about the organisation time series data in the Hunnin Mesh server and will illustrate how the system is designed to achieve high throughput in terms of both measurement ingestion rates and also access to data by end users through a RESTful API.
The Huninn Mesh Network
Huninn Mesh manufactures wireless sensors that measure temperature, pressure, humidity and so on. The sensors are arranged into a
mesh network. That is, a network where one sensor 'node' can pass information to another mesh node, and so on, until a gateway device is reached. The gateway then passes measurements to a server that resides in the cloud.
 |
| Huninn Mesh is a mesh network of sensor nodes (blue) which communicate using the Huninn Mesh protocol (orange lines) through a gateway (purple) to a server in the cloud (black line). |
A Huninn Mesh
network is:
- software defined (routing of messages is under the control of a server in the cloud;
- able to efficiently handle large number of hops between network nodes;
- resilient (it is able to recover from the failure of a node); and,
- quiescent for most of the time (nodes are quite literally off line, relying on schedule specified by the server to perform allocated tasks).
A Huninn Mesh
sensor is:
- compact (10cm by 10cm by 1.5cm);
- typically measures two to three parameters - temperature, pressure and humidity being the most common;
- battery powered; and,
- designed to provide a realistic battery lifetime when deployed in the field of five years and is sampling at 15 second intervals.
A Huninn Mesh
server is responsible for:
- managing the mesh (creating and updating the software defined network);
- managing sensors;
- ingesting data from sensors;
- storing data in a time series database; and
- exposing an API through which the data can be queried.
The characteristics of battery powered sensor nodes coupled with a software defined mesh network topography mean that large numbers of Huninn Mesh sensors can be deployed by non technical people in a very short time and, therefore, at a low cost. The server architecture leverages the power of cloud based computing and mass storage, again, at a low cost.
Using the Data Stream
To date, Huninn Mesh networks have been installed in office buildings in order to provide the measurement base on which building managers can optimise building comfort and energy usage.
Using a real world example of a fifty floor building in New York, over two hundred sensors were deployed, each of which samples temperature, pressure and humidity at roughly fifteen second intervals. Thus, the server receives approximately 2,400 measurements per minute from this network (this
measurement ingestion rate of 40 transactions per second is roughly 1/5,000th the capacity of a single server - we regularly test at 5,000 tx/sec).
Different users have different requirements of this data set. Interviews with building managers tell us that they require:
- proactive hot/cold/comfort alerts;
- reactive hot/cold reports;
- suite/floor/building comfort state visualisation;
- seasonal heat/cool crossover planning;
- plant equipment response monitoring;
- comparative visualisation of different buildings;
- ad-hoc data query for offline analysis (in Excel);
- and so on.
From the above, it should be clear that:
- a building manager requires aggregate data sets that represent multiple sensors; and,
- in most cases, measurements made at fifteen second intervals provide far more information than the requirement demands (a manager does not require 5,760 data points in order to ascertain the trend in ambient air temperature of a building's lobby over a 24 hour period).
At Hunnin Mesh, the question of how to make our data set fit for these many purposes occupied us for some time. The solution was
decimation and the creation of
Computational Devices and that's what the remainder of this post is about.
Time Series Data Set Decimation
Decimation refers to the (extreme) reduction of the number of samples in a data set (as opposed to one-tenth as implied by
deci). Decimation in signal processing is
well understood. I'll explain how we use the technique in the Huninn Mesh system.
A Huninn Mesh sensor samples at a set rate and this rate must be a power of two times a base period defined for the entire network. In this illustration, the sample rate is fifteen seconds.
 |
| Samples are obtained at a regular interval. |
Our problem is that the number of samples is (often) too large and, therefore, the data set needs to be down-sampled. The Huninn Mesh server does this via decimation - it takes a pair of measurements and calculates a new value from them.
 |
| A pair of samples taken at 15 second intervals (black) is used to create a new sample (blue) which contains the maximum, minimum and average of the two raw measurements and has a sample rate of half that of the original pair and with a timestamp half way between the timestamps of the two measurements. |
The calculation of the aggregate value depends upon the type of 'thing' being down-sampled. In the case of a simple scalar value like a temperature measurement, the maximum, minimum and average of the two samples is calculated. This aggregate sample is stored in a Cassandra database in addition to the raw data series.
Decimation is also applied to values created by the decimation process. With four samples, the system is able to decimate a pair of decimated values (using a slightly different algorithm).
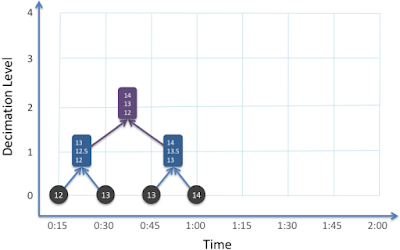 |
| Decimation (purple) of a pair of decimated values (blue) which are calculated from the raw time series samples (black). |
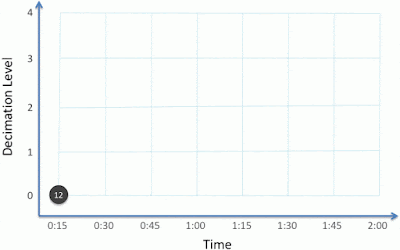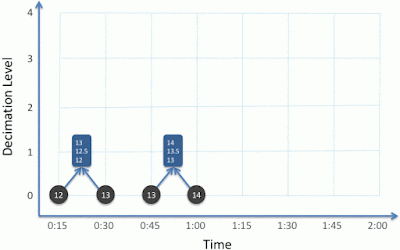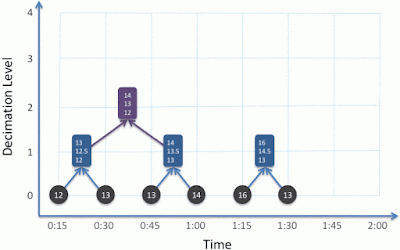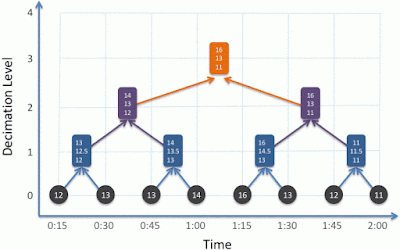
And with eight samples, a third decimation level can be created and so on:
 |
| Three 'levels' of decimation (orange) require 2^3 = 8 raw time series samples and each individual derived value and is representative of the entire two minute period. |
The calculation of decimated values proceeds as shown in the following animation.
 |
| The calculation of aggregate values representing different decimation levels occurs when the full sample set for the aggregation is available. |
A Huninn Mesh server is typically configured decimate over 24 levels
from the base period of the network with the first level aggregating over 2 samples, the second 4, the third 8, to the 24th which aggregates 16,777,216
base period samples. In fact, for any given decimation level, only the pair of values from the previous level are required to perform the decimation meaning that the process is computationally efficient regardless of the decimation level and requires a small working set in memory.
The raw time series measurements and all decimated data products for every sensor are stored in a Cassandra database. The API to query this information will be discussed in a follow up post.
Recall from an
earlier post that every Huninn Mesh device in a network has a sample rate that is a power of two of a base period that is constant for the entire network. Therefore,
decimation intervals exactly match sample intervals allowed for sensors.
A fixed base period and the rule that sensors must sample at a rate that is a power of two times the base period provides a guarantee higher order decimations will be available.
Samples are all aligned in time. In fact, neither samples nor the decimation time window are aligned. Instead, the actual time that a measurement is made depends upon the optimum network configuration. The system only guarantees that measurements will be made at the required interval.
If the base period were set at 400ms, the decimations would proceed as follows:
Decimation
Level |
Samples
Aggregated |
Interval
(ms) |
Time Span
(D H:M:S.ms) |
| 1 |
2 |
800 |
00:00:00.800 |
| 2 |
4 |
1,600 |
00:00:01.600 |
| 3 |
8 |
3,200 |
00:00:03.200 |
| 4 |
16 |
6,400 |
00:00:06.400 |
| 5 |
32 |
12,800 |
00:00:12.800 |
| 6 |
64 |
25,600 |
00:00:25.600 |
| 7 |
128 |
51,200 |
00:00:51.200 |
| 8 |
256 |
102,400 |
00:01:42.400 |
| 9 |
512 |
204,800 |
00:03:24.800 |
| 10 |
1,024 |
409,600 |
00:06:49.600 |
| 11 |
2,048 |
819,200 |
00:13:39.200 |
| 12 |
4,096 |
1,638,400 |
00:27:18.400 |
| 13 |
8,192 |
3,276,800 |
00:54:36.800 |
| 14 |
16,384 |
6,553,600 |
01:49:13.600 |
| 15 |
32,768 |
13,107,200 |
03:38:27.200 |
| 16 |
65,536 |
26,214,400 |
07:16:54.400 |
| 17 |
131,072 |
52,428,800 |
14:33:48.800 |
| 18 |
262,144 |
104,857,600 |
1 05:07:37.600 |
| 19 |
524,288 |
209,715,200 |
2 10:15:15.200 |
| 20 |
1,048,576 |
419,430,400 |
4 20:30:30.400 |
| 21 |
2,097,152 |
838,860,800 |
9 17:01:00.800 |
| 22 |
4,194,304 |
1,677,721,600 |
19 10:02:01.600 |
| 23 |
8,388,608 |
3,355,443,200 |
38 20:04:03.200 |
| 24 |
16,777,216 |
6,710,886,400 |
77 16:08:06.400 |
The Time Span column gives the number of days, hours, minutes, seconds and milliseconds represented by a single decimated value.
Note that earlier, I wrote that the sample period was 'roughly' fifteen seconds. In fact, the network had a base period of 400ms and so the sample period was 12.8 seconds.
The next section provides more detail about the properties of of time periods including alignment with human recognisable intervals.
Properties of the Time Series
At the risk of stating the obvious, the first property of note is that for any given sensor at any moment,
the length of time until the next measurement is available is always known irrespective of whether the measurement is raw data or an aggregate decimated value (this property is very useful and its use will be discussed in my next post about the Huninn Mesh RESTful API for sensor data).
The second property arises as a result of the network having a constant base sample period: device sample rates and decimated sample rates align across a network. Individual devices are constrained such that they must only sample at a rate that is a multiple of a power of two of the base rate. For example, on a network with a 400ms base period, one device may sample every
102,400ms and another 12,800ms and another at 800ms: through decimation, data for all of these devices can be accessed at sample rates that are known a-priori.
The third property is that
time spans for decimation levels do not map exactly to any human recognisable span: no decimation level that maps exactly to an minute, hour, a day, etc.
This last property means that there will always be an error in when estimating values for one of these 'human' periods. For example, what if the daily average for a temperature sensor is required by a building manager? Since there is no decimation that maps exactly to a day, the trick to using these data products is to select a decimation level that provides the smallest number of samples (with an acceptable error for the period under investigation) and then to calculate the mean from this small set.
Where a single sample is required to summarise a day, the following decimations might be considered:
- Decimation level 18 provides a single sample that spans one day, five hours, seven minutes, 37 seconds and 600 milliseconds. This is unlikely to be of use because it spans more than a day and individual samples do not align on date boundaries.
- Decimation level 6 samples at 25,600ms which divides exactly into 86,400,000 (the number of milliseconds in a day). At this decimation level, there are 3,375 samples per day which would have to be averaged in order to calculate the required data product. This represents 1/64 of the raw data volume but the maximum error of 25.6 seconds may be overkill for the requirement.
- Decimation level 10 creates a sample every 409,600ms (about every six minutes and fifty seconds), each sample aggregates over 1,024 raw measurements, returns 210 measurements per day that must be averaged to provide the end result and has a sample error of 6 minutes 24 seconds.
- Decimation level 14 creates a sample every 6,553,600ms (about every one hour and 39 minutes), each sample aggregates over 16,384 raw measurement, returns 13 measurements per day that must be averaged to provide the end result and has a sample error of 20 minutes and 3 seconds.
In the web based API provided by Huninn Mesh for building managers, we chose decimation level 10 which returns 210 samples that then have to be averaged to provide the mean for the day. This decimation level was chosen because the sample time error was small (a maximum of six minutes and ten seconds) and this number of samples also accurately catches trends in temperature / pressure / humidity in a building and so the data set is also useful for graphing.
In this discussion, the sample error refers to that part of a day that is under sampled when using the given decimation level (a user could also choose to over sample in order to fully bracket the required time span).
In summary, the properties of the raw time series and decimated data products mean that the system does not provide answers to questions like "what is the average temperature for the day for sensor X". Instead, the system creates and stores multiple data products that can be rapidly queried and post processed by the user to arrive at an answer.
Computational Devices
Up until this point, discussion has been concerned with measurements from physical sensor devices - little boxes that measure temperature, pressure, humidity and so on. One of the use cases presented for the instrumented building discussed earlier was what is the average, maximum and minimum temperature for the entire building, that is, a measurement that represents a number of other measurements.
Computational devices are a special class of virtual device, implemented in software, that sample measurements from other devices (both real and computational) and emit a sample of their own.
For example, an Aggregating Computational Device may be created that takes as its input all of the devices that produce an aggregate temperate value for every floor in a given building. The devices for the floor are themselves computational devices that take as their input all of the raw temperature sensors on the given floor.
 |
| Nine 'real' devices (blue) measure temperature on three different floors and are used as inputs to three Computational Devices (tc[1]... tc[3]), each of which aggregates over the temperature for an entire floor and are used as inputs to a single computational device (tc[b]) that aggregates over the temperature for the entire building (right). |
In the diagram, above, the arrows between devices show the logical flow of data, arrows should be interpreted as meaning 'provides an input to'.
Just like every other device, Computational Devices sample - they are scheduled at a set rate. They do not wait for events from dependent devices and, for this reason, circularities can be accommodated - a Computational Device can take as input its own state. Sampling theory says that a Computational Device should sample at twice the frequency of the underlying signal: twice as often as the smallest rate of any of the 'real' sensors.
To date, two types of Computational Device have been created:
- Aggregating Computational Devices sample either real devices or other Aggregating Computational Devices and emit the average, maximum, minimum, average-maximum and average minimum; and,
- Alerting Computational Devices sample either real devices or other aggregating computational devices and emit either an enumerated value (e.g. hot, cold, normal).
We have a range of other devices in the works, for example, ASHRAE comfort devices for summer. Ultimately, Huninn Mesh intends to release a public API whereby users can plug their own computational devices into the system.
The output from a
Computational Device is subject to decimation, just like any other device. Time series data from computational devices is stored in a Cassandra database, just like any other data. A computational device is, however, able to specify its own format for storage in the database and its representation through the Huninn Mesh RESTful API.
Programatically, Computational Devices are described by a simple programming interface in Java. It is a straightforward matter for a competent software developer to implement new types of device - for example, a simple extension to the Aggregating Computational Device is one which weights its inputs.
Time Series Data a Device is Immutable
A final rule worth touching upon is that the raw time series and the associated decimated data set for a device is immutable: once created, it cannot be altered. Data is written once to Cassandra and read many times.
What happens then if there is an error? for example, a device is deployed for some time before it comes to light that the calibration is incorrect? (As it happens, this was our most common error during development.)
The system is architected so that sensors do not perform conversion or calibration in the network. Instead, the raw bitfield is always passed to the server which:
- stores the raw bitfield in Cassandra against the ID of the Real Device; and,
- converts, calibrates and decimates measurements and stores these against a Virtual Device ID in Cassandra.
Calibration and conversion is a property of a Virtual Device's specification. If the calibration is changed retrospectively, a new Virtual Device is created for the affected Real Device and historical data replayed to create a new time series.
Put another way, fixups are not allowed - time series data really is immutable. This is not to say that corrections cannot be made, they can. A new Virtual Device is created and the raw data stream is replayed, recreating a new, correct data set. The same is then done for all downstream Computational Devices including their descendant Computational Devices.
This begs one question: if Virtual Devices are subject to change, how does an end user discover what device represents what property - which device can tell me the average temperature for building A?
The answer to this question is in a device discovery API and this will be discussed in my next post about the Huninn Mesh RESTful API.
It's About Scale
Fixing the network's base sample period, the power of two times base period rule, decimation, computational devices, device virtualisation, and immutability are all features that have been honed with one need in mind: performance at scale.
Consider that:
- For any decimation level, the arrival time of the next sample is known in advance, or, put another way, the expiry time of the current measurement is precisely known.
- Reduction of the time series through decimation has a low computational overhead and can dramatically reduce the amount of data required to answer any given query.
- Immutability of any measurement point at any level of decimation for a virtual device means that the sample never expires: it can be safely cached outside of the system forever.
- Indirection through device virtualisation introduces the need for a discovery API, the results of which are the only part of the system subject to change.
In my next post, I will discuss how all of this comes together in the Huninn Mesh RESTful API to deliver a system with very low query latency times across very large numbers of sensors and multiple orders of magnitude of time ranges.










